Why GPU Infrastructure Operations Must Evolve in the Agentic AI Era
June 1, 2026

One of the biggest shifts in the AI industry in 2026 is the mainstream arrival of Agentic AI.
It took center stage at both NVIDIA GTC 2026 and KubeCon EU 2026, and on the ground, AI agent-driven workloads are growing rapidly.
Yet one question hasn't been discussed enough: what does this shift actually demand from GPU infrastructure operations?
What Makes Agentic AI Different
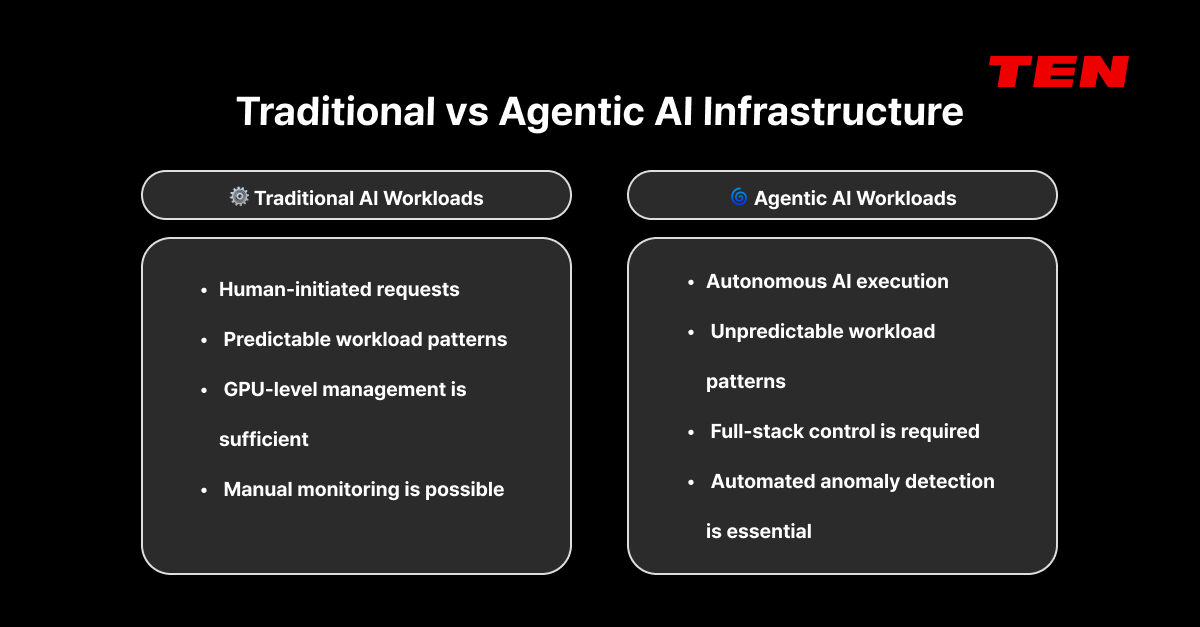
The biggest difference between traditional AI workloads and agentic AI workloads is autonomy.
In the traditional model, a person submits a job, the scheduler allocates resources, and results come back — a predictable flow.
Agentic AI breaks that pattern. The AI reads files, writes code, runs tests, executes multiple tasks in parallel, and dynamically invokes sub-workflows or other agents as needed. It autonomously accesses external services, databases, and APIs, breaking down complex tasks on its own. And throughout all this, these agents continuously and dynamically consume GPU resources.
The New Problems Agentic AI Creates for Infrastructure
From an infrastructure operator's perspective, agentic AI introduces an entirely new class of problems:
Resource contention becomes unpredictable. In environments where humans submit jobs, workload patterns are at least somewhat predictable. Agents are not — there's no way to know when or how much they'll consume. When multiple agent-driven workloads compete for resources simultaneously, you get resource contention, growing pending queues, and noisy neighbor performance interference.
Security boundaries blur. If you can't clearly define what an agent can access and what data it can read or write, you're one step away from a security incident. This becomes especially serious when agents from multiple teams share the same infrastructure.
Cost attribution breaks down. When agents autonomously spawn sub-agents and call multiple services, accurately tracking resource consumption becomes nearly impossible. Without that, you simply can't tell which task generated which cost.
Anomaly detection falls behind. Agents move faster than humans. Traditional manual monitoring can't catch agent-driven anomalies in time.
As the number of agents grows, the complexity of all these problems scales exponentially.
GPU-Level Control Alone Isn't Enough
The infrastructure challenges of an agentic AI environment can't be solved by GPU resource management alone.
Agents don't just consume GPUs. They pull container images, read and write to storage volumes, and access external services over the network. In other words, they consume resources across the entire infrastructure stack.
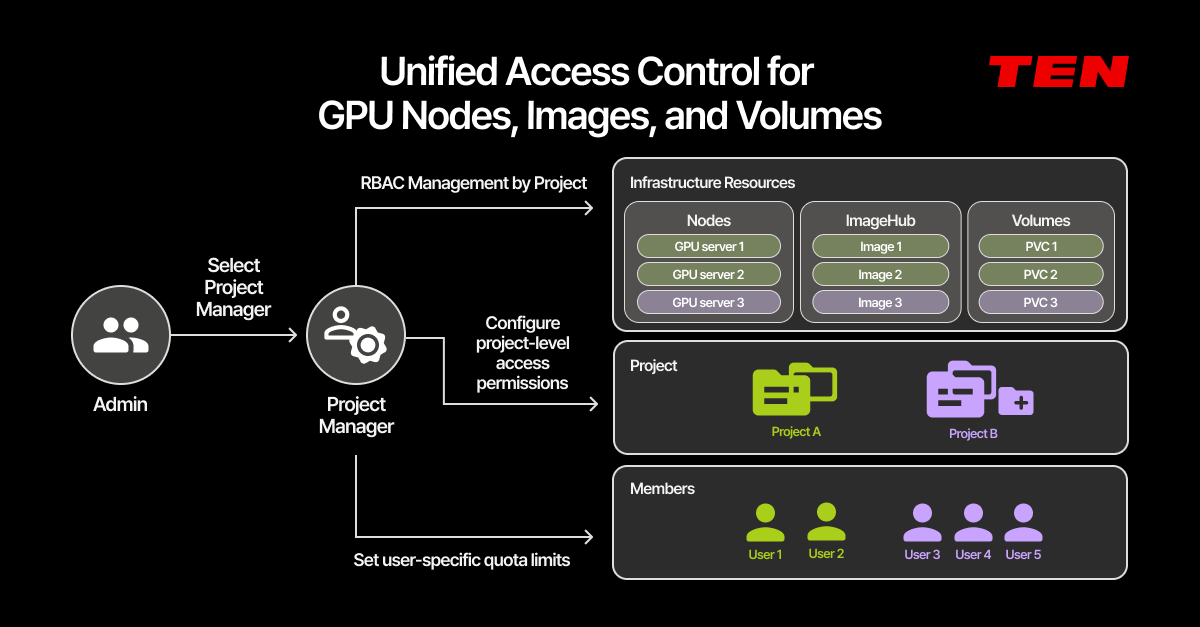
That's why infrastructure operations in the agentic AI era need to control access — at the team, project, and role level — not just to GPUs, but to nodes, image hubs, and storage volumes as well.
When multiple agents or teams share the same hardware, Role-Based Access Control (RBAC) isn't a "nice-to-have." It's the foundation of security.
What AIPub Delivers in Agentic Environments
TEN's AIPub provides the operational foundation that agentic AI demands:
- Full-stack RBAC AIPub manages GPU nodes, container images (ImageHub), and storage volumes as a unified resource set. This set is safely partitioned by user, team, and project to prevent cross-interference. The hierarchy is clear: Admins designate Project Managers, who then configure granular access rights for their members.
- Block-level resource isolation The ability to slice one GPU into 100 blocks through spatial partitioning matters even more in agentic environments. It minimizes resource interference between agents, so one agent's runaway consumption doesn't impact others.
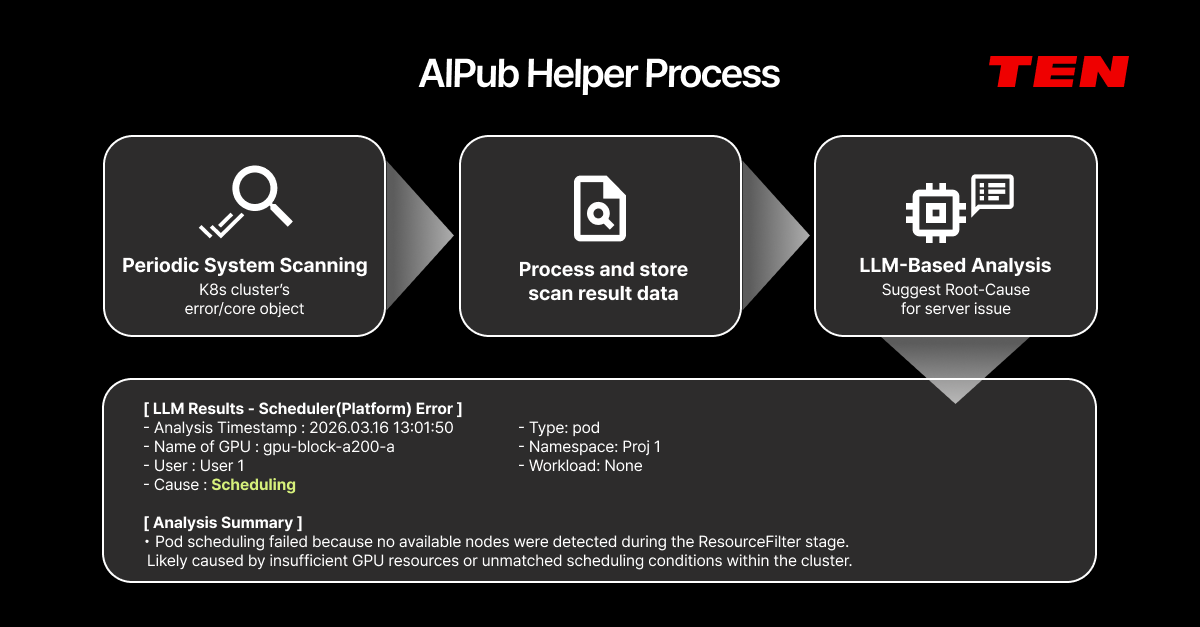
- Real-time monitoring with anomaly detection and RCA support AIPub tracks 100+ metrics in real time — from the data center down to the container level (40 of them are TEN's own, beyond the K8s defaults). Beyond GPU utilization, memory, power, and temperature, it monitors PCIe traffic, NVLink bandwidth, and XID errors. AIPub Helper scans the system on a regular cadence and uses LLM analysis to automatically surface root causes and remediation steps for server failures.
- Usage-based billing and chargeback When agents consume resources autonomously, accurate cost attribution is non-negotiable. AIPub tracks usage at the block level, enabling objective cost allocation by team and project, with minimal cross-workload interference. Daily, weekly, and monthly reports are generated automatically.
- GPU power optimization When agents run on GPUs 24/7, power costs climb fast. AIPub provides fine-grained control over per-card power limits and SM/memory clocks, maintaining performance while optimizing power consumption. The platform is designed to extend into smart grid integration for time-of-use pricing and workload-level carbon tracking.
Is Your Team Ready to Scale Agentic Workloads Safely?
Agentic AI isn't a future story anymore. AI agents that autonomously write code, run tests, and deploy are already in production.
In financial services, agents analyze market data in real time and make automated risk decisions. On manufacturing floors, agents update defect detection models on their own and run inference 24/7 across production lines. In research institutions, multiple teams' agents simultaneously design experiments and spawn sub-agents for parallel training. GPUaaS providers now manage clusters where dozens of customer agents autonomously consume resources side by side.
Across all these environments, the foundational requirements are the same: control and track, in real time, what agents access and how much they consume. Apply access control across the full stack, and catch anomalies early in fast-changing agent-driven workloads.
If your team can't confidently answer the questions below, it's time to revisit your infrastructure operations:
- ✅ Is access controlled at the team and project level — not just for GPUs, but for nodes, image hubs, and storage?
- ✅ Can you accurately track and bill the resources agents consume autonomously, by team and by project?
- ✅ When failures or anomalies happen, can the system identify the root cause and respond before a human steps in?
Organizations without this foundation will hit a wall — not in GPU capacity, but in operational complexity. In the end, agentic AI isn't about "how many GPUs you own." It's about how reliably and predictably multiple agents and teams can share a single infrastructure.
AIPub brings together everything agentic AI infrastructure needs in a single platform: spatial-partitioning-based resource isolation, full-stack RBAC, real-time monitoring, LLM-driven anomaly detection with AIPub Helper, and precise usage-based billing.
If you're designing GPU infrastructure from scratch, RA:X's benchmark-driven consulting helps you determine — with data — exactly which GPUs to deploy and how many.
Don't navigate this alone. Talk to TEN's experts and design the right infrastructure strategy for your organization.
Related reading