The Structural Limits of Time-Slicing: How Spatial Partitioning Solves the 30% GPU Utilization Problem
May 6, 2026

A recent CNCF (Cloud Native Computing Foundation) report revealed that GPU utilization at most organizations remains as low as 5–10%. While the causes of GPU waste vary, GPU partitioning technology is often one of the first recommended solutions due to its potential
for immediate impact.
But partitioning isn't always the right answer. Adopting it without fully understanding the differences between partitioning methods can actually make your AI operations less efficient.
Per-container resource usage repeatedly exceeds intended levels, AI service performance becomes unpredictable, and the accuracy of billing and chargeback breaks down.
At the center of this problem is time-slicing, the most widely used partitioning method today. In this post, we break down the structural limitations of time-slicing and compare how spatial partitioning (block-level partitioning) fundamentally solves these issues.
Two Ways to Share a GPU
When multiple teams or services share GPU resources, there are two main approaches to partitioning.
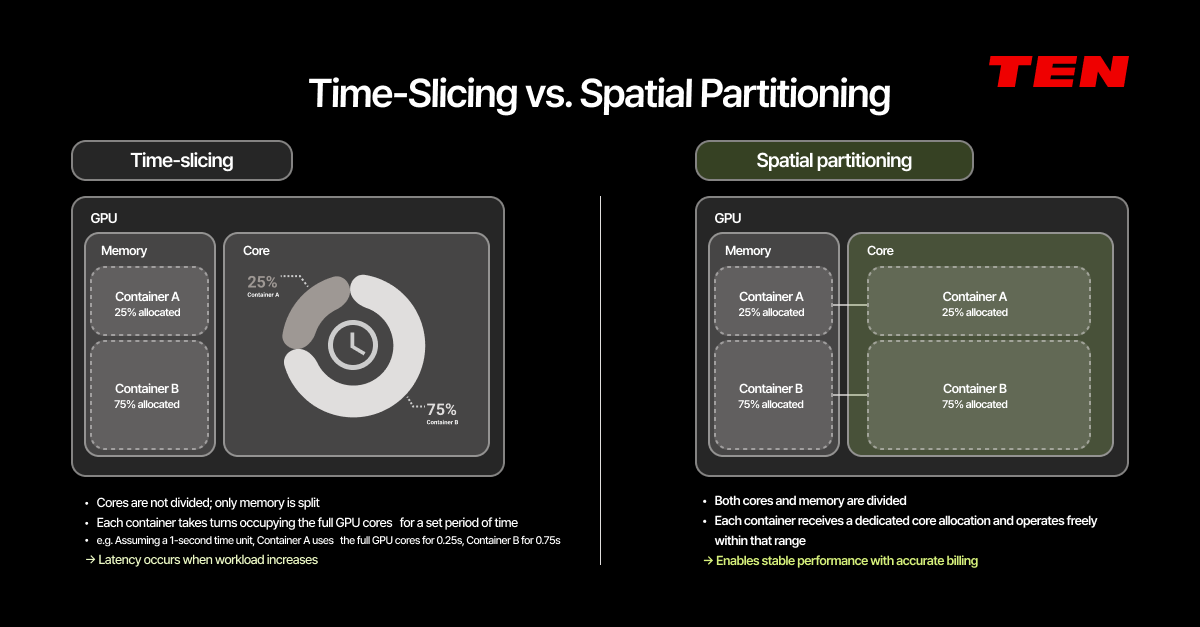
Time-Slicing
Time-slicing divides GPU memory across containers but does not divide the cores. Instead, each container takes turns using the full GPU cores for a set period of time. For example, if we assume a 1-second time unit, Container A uses the full cores for 0.25 seconds, then Container B uses them for 0.75 seconds.
On paper, an 80:20 split looks clean. In practice, those boundaries are rarely precise.
Spatial Partitioning
Spatial partitioning divides both the cores and the memory. Each container receives a dedicated slice of GPU cores and operates exclusively within that allocation. No matter how busy another container gets, your resources remain completely unaffected.
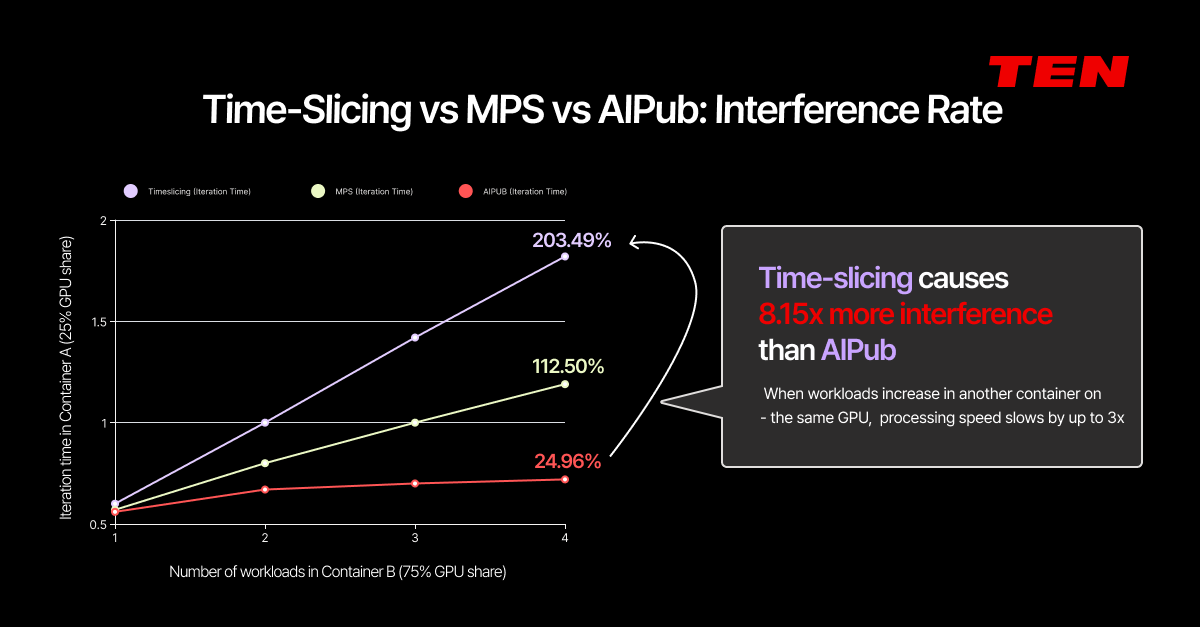
The Real Problem with Time-Slicing: 8.15x Higher Interference
Measured data tells the story more clearly than theory.
In AIPub's internal benchmarks, two containers were run simultaneously on the same GPU: Container A (25% allocation) and Container B (75% allocation). The result: time-slicing produced 8.15x higher interference compared to AIPub's spatial partitioning approach.
When Container B's workload increased, Container A's processing speed slowed by up to 3x in the time-slicing environment. Under spatial partitioning, performance variation was negligible under the same conditions.
 Here's what's happening under the hood:
Here's what's happening under the hood:
Time-slicing splits memory between Container A and B, but the cores are shared on a time basis only. The moment Container B starts consuming even slightly more GPU than usual, it encroaches on Container A's core time. Container A's iteration time increases, latency spikes, and the resources it was promised are no longer guaranteed.
The core issue is this: Container B using more resources should not degrade Container A's performance. But in a time-slicing architecture, this interference is structural and unavoidable.
This problem surfaces most acutely in two scenarios.
- Enterprise AI service operations. For organizations running commercial or internal AI services, this is where the problem hits first. High interference makes consistent service performance nearly impossible. When multiple services share a single GPU, overall performance degrades. For AI infrastructure managers, there's an even more practical concern: when teams need to plan next year's AI infrastructure budget or apply internal chargeback across departments, a mismatch between actual usage and perceived performance creates pushback. When the response is repeatedly "We couldn't even use what we were allocated, so why are we paying the same amount?", the infrastructure team's credibility erodes.
- GPUaaS providers face severe billing problems. Imagine a GPUaaS provider splits one GPU into containers and sells each to a different customer. Customer A is using their allocated share normally. But the moment Customer B increases their workload, Customer A's performance drops, even though Customer A is paying the same price. They didn't get the resources they were promised.
When the gap between expected and actual usage grows this wide, accurate pay-as-you-go billing for fractional GPUs becomes structurally impossible. The foundation of billing itself is compromised.
Spatial partitioning eliminates this problem entirely. Because both cores and memory are physically separated, Container B's workload has zero impact on Container A's resources. Billing is calculated accurately based on each block's actual usage.
AIPub's Approach: One GPU, Up to 100 Blocks
TEN's AIPub divides a single GPU's cores and memory into 1% increments, creating up to 100 discrete blocks.
The core advantages of this architecture:
- Interference-free operation across multi-service and multi-user (multi-tenant) environments. Each block is independently allocated, so one service or user's load never affects another. Whether multiple users share GPU infrastructure during the development phase, or multiple production services are served from a single GPU, both customer segments' needs are met without interference.
- Compatible with Kubernetes scheduling, while delivering GPU control beyond the default scheduler. Block-level GPU resources integrate naturally into Kubernetes' native scheduling framework. But AIPub goes further, providing spatial-partitioning-based resource isolation and operator-level priority control. Detailed scheduler comparisons are covered below.
- MIG support included. NVIDIA's MIG (Multi-Instance GPU) technology partitions at the hardware level into up to 7 instances. AIPub offers MIG as an option alongside its software-based 100-block partitioning. Administrators can choose MIG, Full GPU, or Block partitioning per node based on workload characteristics.
World's First: Dynamic Allocation on Spatial Partitioning
Easy in Time-Slicing, Hard in Spatial Partitioning
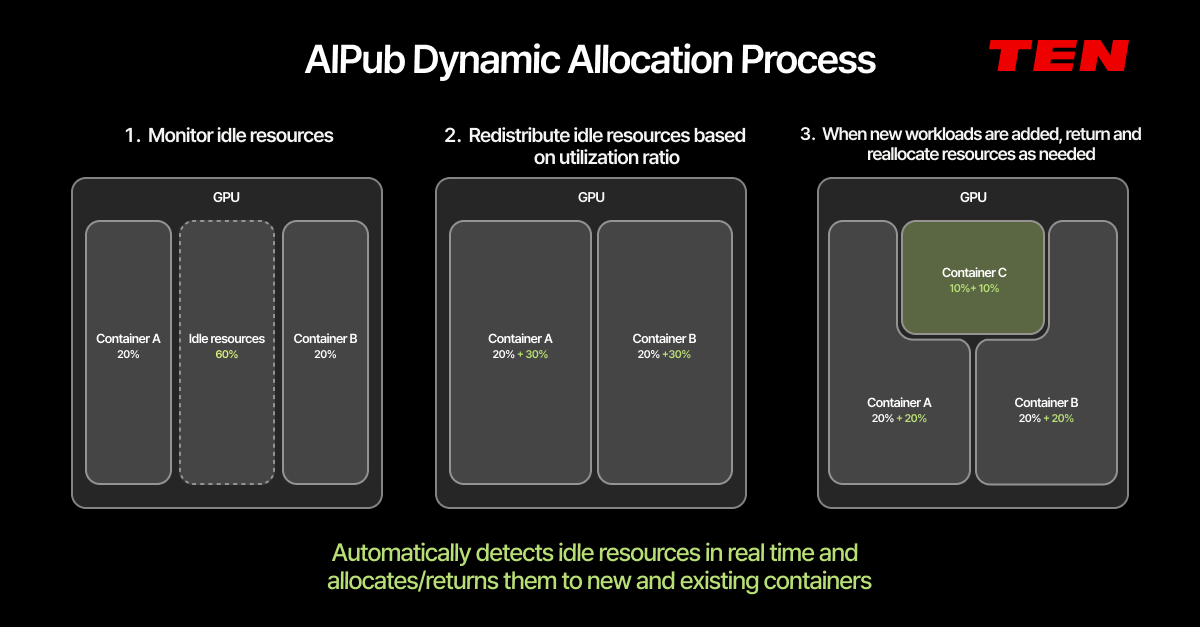
Even when GPUs are finely partitioned, idle time still means wasted resources. AIPub solves this with the world's first dynamic allocation built on spatial partitioning technology.
Time-slicing can implement dynamic allocation relatively easily by simply adjusting usage time windows. That's why most time-slicing platforms support it by default.
Spatial partitioning-based dynamic allocation is a fundamentally different challenge. We'll explore the technical depth of this in upcoming content.
AIPub detects idle resources in real time and automatically redistributes them based on each container's current utilization ratio. When new workloads are added, resources are automatically returned and redistributed as needed.
For example, if Container A (20%) and Container B (20%) are running on a GPU with 60% sitting idle, AIPub automatically redistributes that idle capacity to A and B. When a new Container C is added, previously expanded resources are automatically returned, and the entire allocation is re-optimized across all active workloads.
Scheduler Comparison: Why AIPub's Scheduler Is Different
Partitioning method is only half the equation. Even perfectly partitioned resources are wasted if workloads aren't placed optimally. That's where the scheduler comes in.
Comparing the major schedulers in the Kubernetes ecosystem makes the differences clear.
- Kubernetes default scheduler (kube-scheduler). Handles sequential, pod-level scheduling. Limited GPU-aware scheduling and fine-grained GPU resource control. Risk of deadlocks and infinite pending states due to sequential processing.
- Volcano. Specialized in gang scheduling, allocating all pods belonging to a single job simultaneously. However, uses an all-or-nothing approach where insufficient resources cause the entire job to wait. No operator-level manual priority re-ordering capability.
- KAI Scheduler (NVIDIA/Run:ai, open-sourced). Supports time-slicing-based GPU sharing. However, without core isolation, internal GPU resource interference causes high variability in performance and latency. Not recommended for production environments requiring strict SLAs.
- AIPub Scheduler (✅developed in-house by TEN). Optimized for spatial partitioning-based GPU partitioning. Specialized in resource isolation to prevent inter-workload interference. Supports gang scheduling. The key differentiator: operators can change priorities and force resource reclamation in real time. Preemption has been fully developed but is intentionally not enabled in AIPub, reflecting TEN's product philosophy of prioritizing predictability and stability in service operations. Additionally, by the end of June, all schedulers mentioned above (kube-scheduler, Volcano, KAI, etc.) will be available as selectable options within the AIPub platform, allowing teams to choose the right scheduler based on workload characteristics.
The Real Root of GPU Utilization Problems
GPU utilization falling short of expectations isn't caused by a lack of GPUs.
Time-slicing has a structural limitation: it shares cores on a time basis while only splitting memory. In this architecture, increased workload on one side causes interference on the other, makes performance unpredictable, and breaks billing accuracy. You've partitioned the resources, but you can't actually use them reliably.
In industries where service uptime directly impacts business outcomes, this goes beyond inefficiency and becomes an operational risk. In financial services, if an AI-based fraud detection system's response is delayed due to interference, real-time blocking can fail. In manufacturing, if a defect detection AI's inference latency becomes unstable, defective products ship. In defense and healthcare, where not a single delay is tolerable, time-slicing's interference problem is itself the risk.
✅ Spatial partitioning (block-level partitioning) solves this at the root. Physical separation of both cores and memory eliminates inter-workload interference entirely. Block-level usage tracking ensures billing and chargeback accuracy. Add the world's first spatial partitioning-based dynamic allocation, and you have a complete system that automatically reclaims and redistributes idle resources.
🔎 Before purchasing additional GPUs, examine how your current GPUs are being partitioned and operated.
AIPub provides spatial partitioning, dynamic allocation, scheduling, and monitoring in a single platform for maximum GPU utilization. If you're at the stage of deploying new GPU infrastructure, RA:X's benchmarking-based consulting can help you determine the right GPU configuration with data, not guesswork.
👉 Learn more about AIPub
👉 Inquire about RA:X consulting
📩 Talk to our team