Extreme Co-Design이란 무엇인가: NVIDIA가 바꾸는 AI 인프라 구조 : 칩(Chip)에서 랙(Rack)으로
2026년 5월 11일

본 글은 NVIDIA GTC 2026을 앞두고 엔비디아의 핵심 전략인 'Extreme Co-Design'을 분석하는 5부작 시리즈의 두 번째 편입니다.
1편에서 우리는 딥시크(DeepSeek)가 주어진 하드웨어 제약 속에서 소프트웨어와 알고리즘을 극한으로 최적화한 사례를 다뤘습니다.
👉 DeepSeek 쇼크와 Extreme Co-Design: NVIDIA가 정의하는 AI 인프라의 미래
이번 편에서는 NVIDIA가 그보다 한 걸음 더 나아가 하드웨어의 물리적 단위 자체를 어떻게 다시 정의하고 있는지를 살펴봅니다.
왜 젠슨 황은 “무어의 법칙은 끝났다”고 말했을까?
지난 수십 년간 반도체 산업은 더 작은 트랜지스터를 더 많이 집적하는 방식으로 성능을 높여 왔습니다.
이른바 무어의 법칙(Moore’s Law) 입니다
하지만 AI 시대, 특히 생성형 AI가 단순한 생성(Generation)을 넘어 Reasoning 단계로 진입하면서 상황이 달라졌습니다.
추론 과정은 기존보다 훨씬 더 많은 연산을 요구하며, 경우에 따라 컴퓨팅 수요가 수십 배에서 100배 이상까지 증가합니다.
이제는 트랜지스터를 조금 더 작게 만들고, 같은 칩 안에 더 많이 넣는 방식만으로는 이러한 폭발적인 연산 수요를 감당할 수 없습니다.
바로 이러한 이유로, 젠슨 황은 수년간 여러 키노트에서 "무어의 법칙은 사실상 끝났다(Moore's Law is dead)"고 반복해서 언급해 왔습니다.
이 말은 단순히 반도체 성능 향상이 멈췄다는 이야기가 아닙니다.
오히려 AI 시대의 성능 혁신은 칩 하나가 아니라, 칩·시스템·네트워크·소프트웨어를 함께 설계하는 방식에서 나온다는 전략 선언에 가깝습니다.
Extreme Co-Design이란 무엇인가
엔비디아가 말하는 Extreme Co-Design은 칩만 잘 만드는 접근이 아닙니다.
- 칩(Chip)
- 시스템(System)
- 네트워크(Network)
- 소프트웨어(Software)
- 알고리즘(Algorithm)
- 데이터센터 인프라(Data Center Infrastructure)
이 모든 요소를 동시에 설계하는 것이 핵심입니다.
즉, 하드웨어가 먼저 나오고 그 위에 소프트웨어가 얹히는 순차적 구조가 아니라,
미래의 AI 워크로드가 요구할 특성을 미리 예측하고, 이에 맞춰 하드웨어와 소프트웨어, 네트워크와 냉각 구조까지 한 번에 설계하는 방식입니다.
이것이 엔비디아가 정의하는 Extreme Co-Design의 본질입니다.
시스템의 해체와 재구성: Disaggregation
 이미지 출처 : https://www.nvidia.com/en-sg/data-center/gb200-nvl72/
이미지 출처 : https://www.nvidia.com/en-sg/data-center/gb200-nvl72/
Extreme Co-Design을 가장 잘 보여주는 대표 사례가 바로 Blackwell NVL72입니다.
기존 GPU 시스템은 보통 서버 한 대에 GPU 8장을 꽂고, 이를 NVLink로 연결하는 방식이 표준이었습니다.
이 구조는 학습(Training) 중심 시대에는 충분히 강력했습니다.
하지만 초거대 MoE(Mixture of Experts) 모델과 reasoning 모델이 등장하면서, 문제는 서버 내부가 아니라 서버 간 통신에서 발생하기 시작했습니다.
GPU 간 데이터 교환이 서버 밖으로 나가는 순간 속도는 급격히 떨어지고, 전체 시스템의 병목이 발생하는 것입니다.
엔비디아는 이 한계를 해결하기 위해 기존 GPU 내부에 묶여 있던 연결 구조를 분리했습니다.
그리고 이를 중앙 NVLink Switch Fabric으로 재구성해, GPU를 더 이상 “칩 내부”가 아니라 랙(Rack) 단위로 연결하기 시작했습니다.
랙이 곧 새로운 칩이다 (Rack is the new Chip)
Blackwell NVL72에서는 72개의 GPU가 하나의 NVLink 도메인으로 연결됩니다.
즉, 랙 전체가 하나의 거대한 연산 유닛처럼 동작하는 구조입니다.
이것은 단순히 GPU 수를 늘린 확장이 아닙니다.
기존의 8-GPU 서버 구조를 여러 대 묶는 수준이 아니라, 랙 자체를 하나의 컴퓨팅 단위로 재정의한 것입니다.
이러한 변화는 곧 Extreme Scale-Up의 시작을 의미합니다.
초당 130TB: 새로운 물리 법칙의 등장
이 거대한 랙 시스템이 실제로 하나의 칩처럼 동작할 수 있는 이유는 NVLink Switch 기술에 있습니다.
NVLink Switch는 수천 가닥의 구리 케이블을 통해 130TB/s 수준의 All-to-All 통신을 가능하게 합니다.
이는 글로벌 인터넷 피크 트래픽에 준하는 수준의 데이터가 단일 랙 내부에서 흐른다는 의미입니다.
이 초고속 통신 구조가 중요한 이유는 명확합니다.
과거에는 서버 간 네트워크가 외부 제약이었는데, NVL72 구조에서는 그 병목을 랙 내부 설계로 흡수하기 때문이죠.
즉, 통신은 더 이상 외부 환경의 문제가 아니라 시스템 내부에서 설계 가능한 변수가 된 것입니다.
AI 인프라 설계 방식이 근본적으로 바뀌기 시작한 것이죠.
공랭의 한계와 액체 냉각의 필수화
하지만 이러한 고밀도 설계는 새로운 문제를 만들어냅니다.
72개의 GPU를 하나의 랙에 밀집 배치하면 전력 밀도는 기존 8-GPU 서버와 비교할 수 없을 정도로 높아집니다.
이 경우 기존의 공랭(Air Cooling) 방식만으로는 발열을 감당하기 어렵습니다.
그 결과, 액랭(Liquid Cooling)은 더 이상 선택지가 아니라 필수 구조가 됩니다.
이 지점에서 데이터센터는 단순히 서버를 설치하는 공간이 아니라,
- 전력
- 열
- 공간
- 네트워크
를 함께 설계해야 하는 물리적 생산 설비로 성격이 바뀝니다.
Extreme Co-Design은 칩 설계의 문제가 아니라 인프라 설계의 문제이기도 한 것이죠.
AI 인프라의 핵심 딜레마: ITL과 Throughput
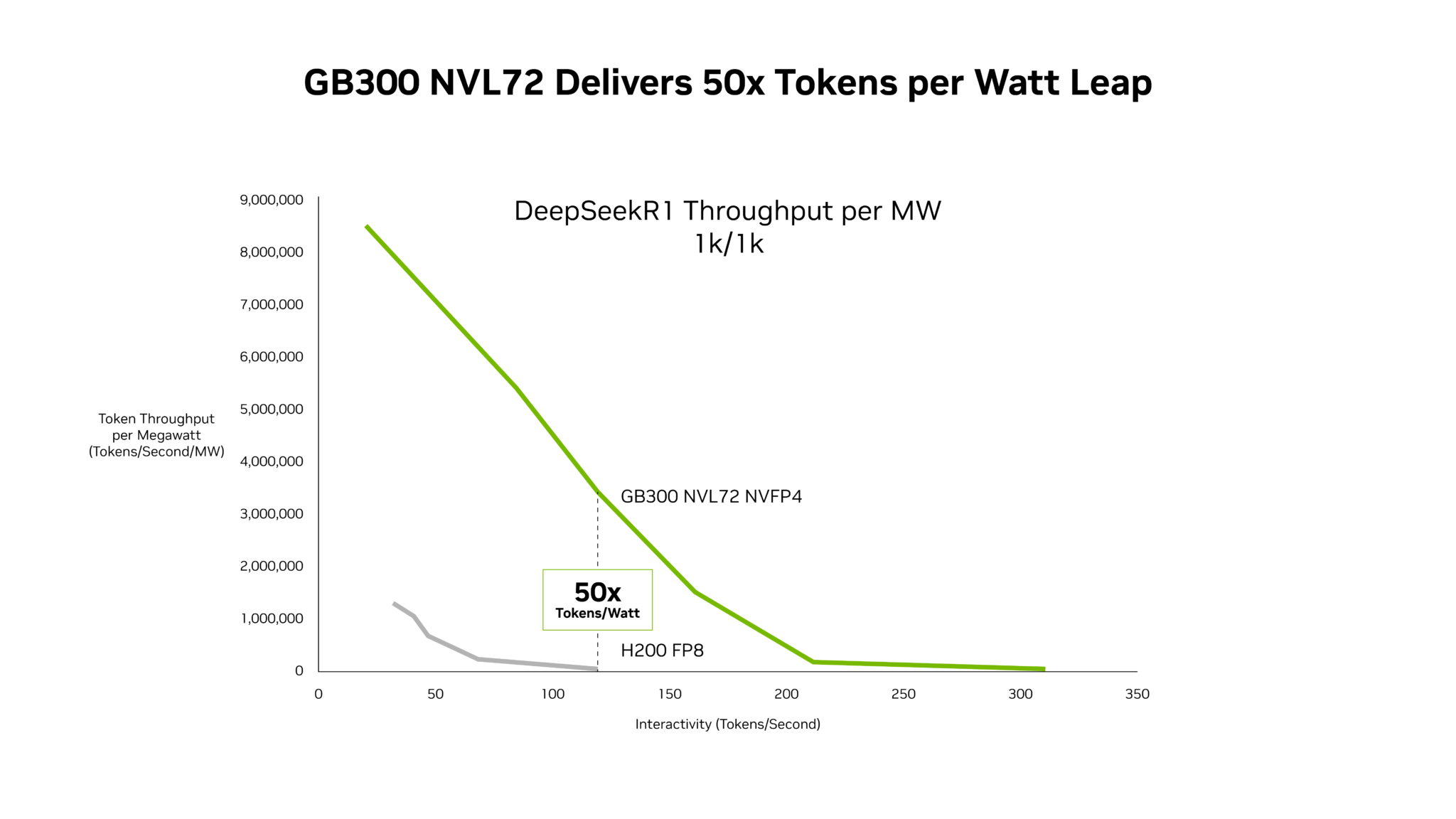 AI 인프라 구축의 가장 큰 난제는 반응 속도(ITL)와 처리량(Throughput) 사이의 트레이드오프(Trade-off)입니다.
AI 인프라 구축의 가장 큰 난제는 반응 속도(ITL)와 처리량(Throughput) 사이의 트레이드오프(Trade-off)입니다.
- ITL (Inter-Token Latency)
ITL은 사용자가 응답을 체감하는 속도입니다.
답변이 끊기지 않고 자연스럽게 생성되는지를 결정하는 지표입니다.
이를 개선하려면 하나의 요청에 더 많은 GPU 자원을 투입해야 하는데, 이 경우 비용 효율은 떨어질 수 있습니다.
- Throughput
Throughput은 단위 시간당 시스템이 처리하는 총 토큰 양입니다.
이는 곧 전체 생산성과 수익성으로 이어집니다.
하지만 Throughput을 높이기 위해 더 많은 요청을 병렬 처리하면, 사용자별 응답 속도는 느려질 수 있습니다.
즉, AI 인프라 설계는 항상 다음 질문과 마주하게 됩니다.
더 빠른 체감 속도를 줄 것인가, 더 많은 토큰을 생산할 것인가?
Reasoning 시대가 이 딜레마를 더 어렵게 만든다
Reasoning 모델은 단순 생성형 모델보다 훨씬 더 많은 연산을 필요로 합니다.
생각하는 과정 자체가 길어지고 복잡해지기 때문입니다.
그 결과, ITL과 Throughput 사이의 균형 문제는 더욱 심화됩니다.
엔비디아의 전략은 이를 하나의 큰 메모리·연산 풀로 해결하는 것입니다.
72개 GPU를 하나의 거대한 시스템처럼 묶어, 모델 전체를 메모리에 올리고 더 유연하게 연산 자원을 활용하는 구조를 만드는 것입니다.
이러한 구조에서는
- 거대 모델을 안정적으로 구동해 ITL을 확보
- 동시에 많은 요청을 처리해 Throughput 증대
두 마리 토끼를 동시에 잡을 수 있습니다.
그리고 이것이 바로 젠슨 황이 말하는 토큰 생성 원가 절감의 핵심입니다.
DeepSeek와 NVIDIA의 차이: 최적화 vs 동시 발명
여기서 DeepSeek와 NVIDIA의 차이 차이가 분명해집니다.
DeepSeek의 방식
주어진 하드웨어 환경에 맞춰 소프트웨어와 알고리즘을 뜯어고칩니다.
PTX 튜닝, DualPipe, MoE 최적화 등의 방법을 통해 제약된 하드웨어 위에서 최고의 효율을 끌어내는 방식입니다.
NVIDIA의 방식
미래의 소프트웨어와 AI 워크로드가 필요로 할 구조를 먼저 예측하고,
그 요구를 만족시키기 위해 칩, 시스템, 네트워크, 냉각 방식까지 함께 설계합니다.
NVIDIA는 단순히 칩을 만드는 회사가 아니라 AI 인프라 전체를 발명하는 회사로 진화하고 있는 것입니다.
AI 시대의 경쟁력은 더 좋은 칩 하나에서 나오지 않는다.
전체 스택을 함께 설계할 수 있는 능력에서 나온다.
Extreme Co-Design은 바로 이 전환을 설명하는 개념인 것입니다.
TEN의 방식
이 변화는 단순히 글로벌 빅테크의 이야기만은 아닙니다.
AI 인프라 경쟁이 하드웨어 확보에서 설계 역량의 문제로 이동하고 있는 만큼, 앞으로 중요한 것은 GPU를 얼마나 많이 보유했는가가 아니라
그 GPU를 어떤 구조로 설계하고 어떤 방식으로 운영할 수 있는가입니다.
TEN은 이러한 변화 속에서 AI 인프라를 단순히 “도입”하는 것이 아니라 목적에 맞게 설계하고 운영하는 방식을 제안하고 있습니다.
👉 AI Pub으로 통합 운영 전략 살펴보기
📩 [전문가와 직접 상담하기]
[다음 글 예고]
그렇다면 이처럼 칩과 시스템, 냉각 구조와 네트워크까지 함께 설계된 거대한 AI Factory는 실제로 어떤 모습으로 구현되고 있을까요?
다음 글에서는 NVIDIA GTC에서 공개된 실물 시스템을 중심으로, 이러한 Extreme Co-Design이 어떻게 reasoning AI 시대를 가속화하고 있는지 구체적으로 살펴보겠습니다.