GPU 스케줄링은 이제 선택이 아니다: KubeCon EU 2026이 확인한 것들
2026년 5월 11일

2026년 암스테르담에서 열린 KubeCon EU 2026은 역대 최대 규모인 13,500명 이상이 참석한 행사였습니다.
그리고 올해의 가장 큰 주제는 분명했습니다. AI 워크로드가 Kubernetes 위에서 본격적으로 운영되기 시작했다는 것이죠.
그 중에서도 인프라 운영자에게 가장 의미 있었던 발표는 NVIDIA의 움직임이었습니다.
NVIDIA가 GPU 스케줄링 도구를 오픈소스로 공개한 이유
KubeCon EU 2026에서 NVIDIA는 세 가지 핵심 프로젝트를 CNCF(Cloud Native Computing Foundation)에 기부했습니다. CNCF는 Kubernetes를 포함한 클라우드 네이티브 기술의 표준을 관리하는 비영리 재단입니다. 여기에 프로젝트를 기부한다는 것은 NVIDIA 독점 기술을 업계 공동 표준으로 전환하겠다는 선언에 가깝습니다.
- GPU DRA(Dynamic Resource Allocation) 드라이버 : Kubernetes에서 GPU를 부분적으로 나눠서 여러 컨테이너에 배정할 수 있게 해주는 도구입니다. 기존에는 컨테이너 하나에 GPU 한 장을 통째로 배정해야 했던 구조를 바꿉니다.
- KAI 스케줄러: GPU 워크로드를 자동으로 최적 배치하는 스케줄러입니다. 어떤 작업에 GPU를 얼마나 배정하고, 우선순위를 어떻게 정할지를 자동으로 결정합니다. 타임슬라이싱 기반의 GPU 공유 방식을 사용합니다.
- Grove: GPU 관련 모니터링과 관리를 위한 도구입니다.
이 발표의 핵심 메시지는 하나입니다. GPU 인프라 관리가 Kubernetes 생태계 차원의 표준 문제로 다뤄지기 시작했다는 것을 의미하죠!

AI 워크로드의 80%가 Kubernetes 위에서 돌아간다
KubeCon의 한 세션에서 공유된 수치가 있습니다. 현재 AI 워크로드의 약 80%가 Kubernetes에서 관리되고 있다는 것입니다.
정확한 수치 여부를 떠나, 방향성은 명확합니다. AI 모델의 학습, 추론, 서빙이 모두 Kubernetes 컨테이너 환경 위에서 이뤄지고 있고, 이 추세는 가속화되고 있습니다.
문제는 Kubernetes가 원래 GPU를 관리하기 위해 설계된 플랫폼이 아니라는 점입니다. CPU와 메모리에 대한 자원 관리는 네이티브로 잘 지원하지만, GPU에 대한 세밀한 제어는 기본 기능으로 제공되지 않죠. 이 때문에 GPU 스케줄링, GPU 분할, 멀티테넌트 격리 같은 기능은 별도의 솔루션이 필요합니다.
NVIDIA가 이번에 기부한 도구들이 바로 이 빈 자리를 채우기 위한 것이라고 볼 수 있습니다.
추론(Inference)이 학습(Training)을 넘어서는 전환점
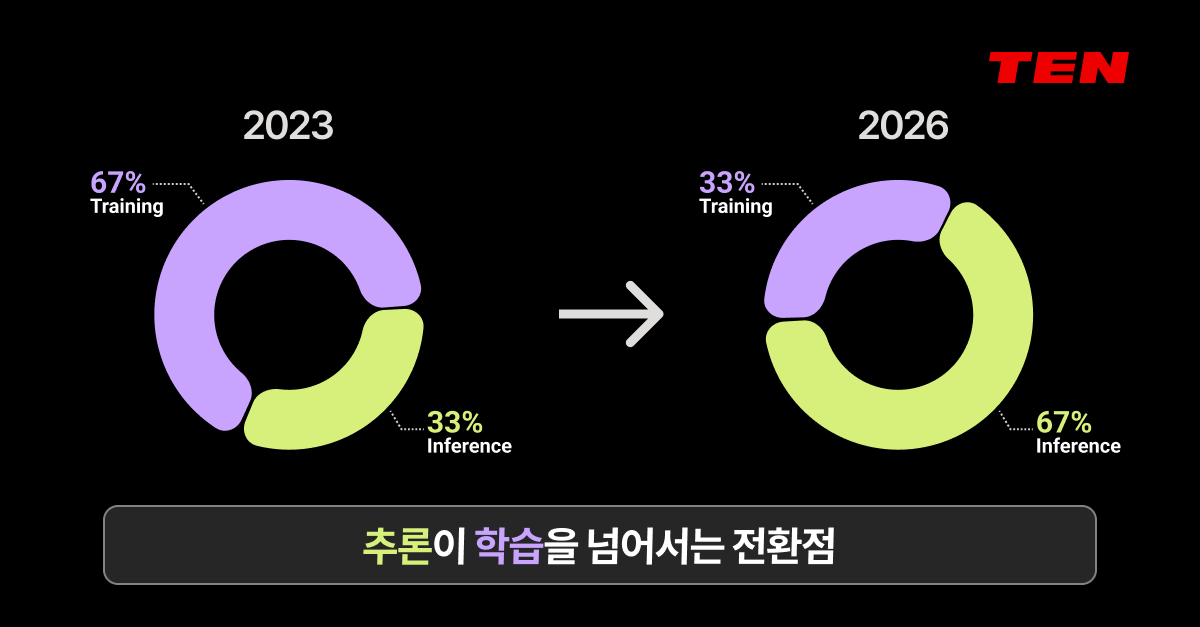 KubeCon 키노트에서 공유된 전망도 주목할 만합니다. 2023년에는 AI 컴퓨팅 수요의 약 2/3가 학습(Training)에 집중됐지만, 2026년 말에는 이 비율이 역전되어 추론(Inference)이 더 큰 비중을 차지할 것으로 예측하고 있습니다.
KubeCon 키노트에서 공유된 전망도 주목할 만합니다. 2023년에는 AI 컴퓨팅 수요의 약 2/3가 학습(Training)에 집중됐지만, 2026년 말에는 이 비율이 역전되어 추론(Inference)이 더 큰 비중을 차지할 것으로 예측하고 있습니다.
추론은 학습과 다른 특성을 갖습니다. 학습은 한 번 집중적으로 하면 끝나지만, 추론은 AI가 생각하고, 판단하고, 행동할 때마다 지속적으로 발생합니다. 에이전틱 AI가 확산되면서 이 수요는 24시간 멈추지 않죠.
이 전환이 인프라 운영에 의미하는 바는 “고정 할당, 수동 스케줄링, 불투명한 사용량 추적”으로는 추론 시대의 GPU 인프라를 운영할 수 없다는 것이죠.
GPU 스케줄링은 이제 "있으면 좋은 기능"이 아니라 "필수 인프라"다
KubeCon EU 2026의 전체 메시지를 한 줄로 요약하면, GPU 스케줄링과 멀티테넌트 격리는 더 이상 선택 사항이 아닙니다. Kubernetes 위에서 AI 워크로드를 운영하는 모든 조직에게 필수 인프라가 됐습니다.
다만, KubeCon 현장에서도 확인된 현실이 있습니다. 데모와 프로토타입은 많았지만, 프로덕션 환경에서 신뢰할 수 있는 수준의 GPU 운영 체계를 갖춘 조직은 아직 소수라는 평가가 나왔습니다.
NVIDIA가 기부한 도구들은 기초 수준(프리미티브)의 기능을 제공합니다. 실제 엔터프라이즈 환경에서 필요한 세밀한 자원 격리, 정확한 빌링, 멀티클러스터 통합 관리, 장애 근본 원인 분석 같은 기능은 이 위에 추가로 구축되어야 합니다.
 ---
---
TEN의 AIPub이 이 흐름에서 갖는 위치
TEN의 AIPub은 Kubernetes 기반 AI 워크로드 오케스트레이션 플랫폼으로, KubeCon에서 논의된 문제들을 이미 상용 수준에서 해결하고 있습니다.
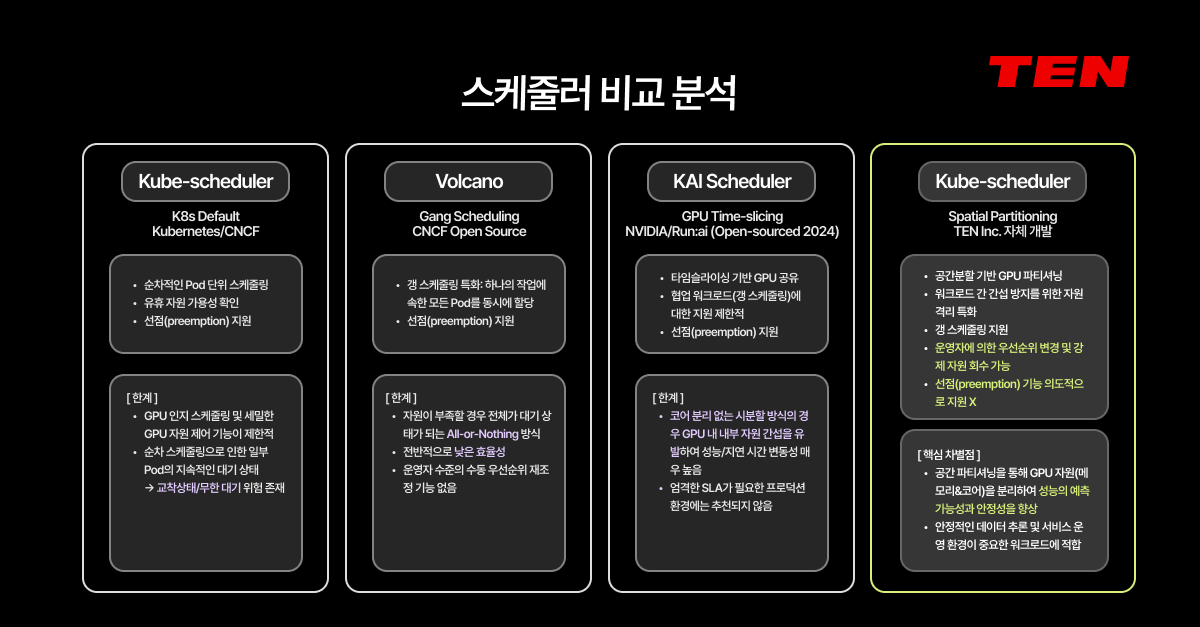
- GPU 100분할 공간분할: NVIDIA가 기부한 DRA 드라이버가 GPU 부분 할당을 지원한다면, AI Pub은 여기서 더 나아가 GPU 1개를 최대 100개 블록으로 분할합니다. 공간분할(Spatial Partitioning) 방식으로 코어와 메모리를 모두 분리하기 때문에, 타임슬라이싱 대비 간섭율이 8.15배 낮습니다.
- 독자 개발 스케줄러: KAI 스케줄러가 타임슬라이싱 기반 GPU 공유를 지원한다면, AI Pub의 스케줄러는 공간분할 기반 파티셔닝에 최적화되어 있습니다. 우선순위에 따른 순차 처리 알고리즘으로 Job의 Pending과 Deadlock 발생을 원천적으로 차단하며, 운영자가 직접 우선순위를 변경하고 자원을 강제 회수할 수 있습니다.
- 엔터프라이즈급 모니터링: 데이터센터 레벨부터 컨테이너 레벨까지, 40개 이상의 자체 개발 지표로 AI 인프라 전체를 실시간 모니터링합니다. 사용량 기반 빌링과 Chargeback까지 지원해 FinOps 체계를 갖출 수 있습니다.
- RBAC(역할 기반 접근 제어): GPU 노드뿐 아니라 컨테이너 이미지, 스토리지 볼륨까지 프로젝트 및 사용자별로 세밀하게 접근을 제어합니다.
2026년 지금, 인프라 담당자에게 던지는 질문
KubeCon EU 2026은 GPU 인프라 운영의 방향을 확인해주는 행사였습니다.
GPU 스케줄링이 Kubernetes 표준이 되고, 추론 수요가 훈련을 넘어서는 시대에, 지금 우리 조직의 GPU 인프라는 이 전환에 준비되어 있는지를 점검할 시점입니다.
지금 여러분 조직의 GPU 스케줄링은 어떤 방식으로 운영되고 있나요?
👉 AI Pub 자세히 보기
📩 전문가와 직접 상담하기
함께 읽어보면 좋은 글