GPU FinOps: AI 시대의 비용 관리가 달라야 하는 이유
2026년 6월 12일

“한 달에 GPU 비용이 5천만 원 나왔는데, 어느 팀이 얼마를 썼는지 모른다고요?”
이 상황은 생각보다 훨씬 흔합니다. GPU 클러스터를 도입한 많은 조직이 비용은 늘어나는데 누가 어떻게 쓰는지 추적하지 못하는 구조로 운영하고 있죠.
2026년 6월, FinOps X 컨퍼런스(샌디에이고)에서 GPU FinOps가 핵심 의제로 등장한 것은 우연이 아닙니다. AI 인프라의 비용 문제가 드디어 산업 전체의 과제로 부상한 것입니다.
문제는 기존 FinOps 방법론이 GPU에는 맞지 않는다는 데 있습니다.
기존 FinOps vs AI FinOps: 무엇이 근본적으로 다른가

FinOps는 원래 클라우드 비용 최적화를 위해 발전한 방법론입니다. CPU 사용률, 스토리지 용량, 네트워크 대역폭을 추적하고, 유휴 인스턴스를 없애고, 예약 인스턴스로 절약하는 식의 접근이 핵심이었습니다.
하지만, AI 시대의 GPU에는 이 공식이 통하지 않습니다. 기존 FinOps가 다루지 못하는 차원들이 있기 때문입니다.
GPU는 "할당"만 해도 비용이 발생합니다. CPU와 달리, GPU는 Kubernetes에서 리소스가 할당되는 순간부터 비용이 발생하죠.
실제로 워크로드가 구동 중인지, 아이들 상태인지와 무관합니다. H100 하나의 시간당 클라우드 비용은 대략 $2~3 수준입니다. 64개 H100 클러스터를 하루 운영하면 약 $4,600, 추론 플롯을 한 달 돌리면 $50,000 이상이 나옵니다. 그런데 이 비용이 어떤 팀의, 어떤 모델에서 발생했는지 추적하지 못한다면, 비용 최적화는 시작할 수조차 없습니다.
그렇기 때문에 cost-per-token이라는 지표가 필요합니다. CPU 기반 서비스에서 "요청당 비용"을 계산하듯, AI 인프라에서는 "토큰당 비용", "추론 요청당 비용"이 실질적인 비용 효율 지표입니다.
단순히 GPU를 몇 대 보유했는지가 아니라, GPU가 얼마나 효율적으로 가치를 만들어내고 있는지가 핵심입니다.
GPU 비용의 가장 큰 블랙홀: idle time
GPU 활용률 30% 미만이 산업 전반의 현실입니다. 나머지 70%는 할당은 됐지만 실제로는 사용되지 않고 있는 상태이죠.
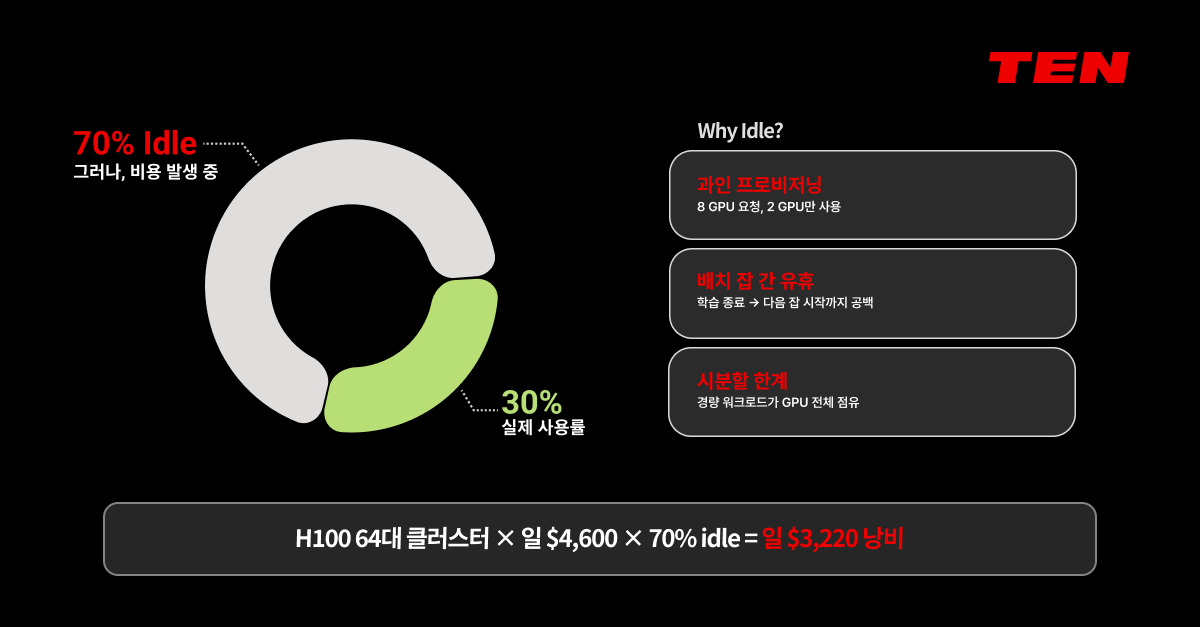
이러한 Idle time이 발생하는 이유는 크게 세 가지입니다.
-
첫째, 과잉 프로비저닝입니다.
팀이 8개 GPU를 요청했지만 실제로는 2개만 사용하는 상황이 반복됩니다. 가져갈 수 있을 때 많이 가져가자는 심리, 그리고 "나중에 더 필요할 수 있다"는 불확실성 회피가 만들어내는 구조적 낭비입니다. -
둘째, 배치 잡(Job) 사이의 유휴 시간입니다.
학습 잡이 끝나고 다음 잡이 시작되기 전까지의 간극, 전처리 완료 후 GPU 할당이 해제되지 않는 상태 등이 모두 idle 비용으로 누적됩니다.
셋째, 시분할 방식의 한계입니다.
기존의 GPU Time-slicing은 코어를 분할하지 않고 메모리만 나눕니다. 경량 워크로드가 GPU 전체를 점유해버리면, 다른 서비스가 기다려야 합니다. 이 구조에서는 GPU를 실제로 필요한 만큼만 정확히 쓰는 것이 불가능합니다.
정확한 비용 귀속이 불가능한 이유
GPU 비용을 추적하려고 Kubernetes 네임스페이스별 모니터링을 설정해 본 팀이라면 이 문제에 부딪혔을 것입니다. K8s는 GPU를 기본적으로 "전체 단위"로만 할당합니다. GPU 1개를 여러 팀이 공유하는 환경에서는 팀별 비용을 객관적으로 분리하는 것이 구조적으로 불가능합니다.
Chargeback 문제는 비즈니스 맥락에 따라 다르게 나타납니다.
-
GPUaaS 사업자: 고객사 A는 GPU 3개를 쓰는데 고객사 B와 공유 클러스터에서 정확히 어떻게 과금할 것인가
-
엔터프라이즈: AI팀, 데이터팀, DevOps팀이 같은 클러스터를 쓰는데 부서별 비용을 어떻게 배분할 것인가
-
대학·연구소: 연구실별 사용량 리포트를 교내 예산 배분이나 외부 과제 정산에 활용해야 하는 경우
이 질문들에 데이터 기반으로 답하지 못한다면, GPU 투자 ROI를 입증하는 것 자체가 어려워집니다.
AIPub이 GPU FinOps를 가능하게 하는 구조
TEN의 AIPub은 이 문제를 블록 단위 자원 배정에서 출발해 해결합니다.
GPU 1개를 코어와 메모리 모두 1% 단위, 즉 100개 블록으로 정밀 분할합니다. 시분할이 아닌 공간분할 방식이기 때문에 각 컨테이너는 할당받은 블록 범위 안에서만 자원을 사용하고, 다른 서비스의 성능에 영향을 주지 않습니다. 실제로 동일 GPU 내 다른 컨테이너의 워크로드가 증가해도 AIPub의 공간분할 방식에서는 서비스 성능 변동이 최소화됩니다.

이 구조가 FinOps에서 중요한 이유는 명확합니다.
블록 단위 배정 → 블록 단위 사용량 추적 → 블록 단위 빌링 으로 이어지는 파이프라인이 만들어지기 때문입니다. GPU를 어떤 팀이 몇 블록 사용했는지, 어떤 프로젝트에서 언제 자원을 소비했는지가 객관적인 데이터로 기록됩니다.
여기에 더해 AIPub의 동적 할당(Dynamic Allocation) 기능이 idle time을 구조적으로 줄입니다. 실시간으로 유휴 자원을 탐지해서 기존 컨테이너에 자동으로 재배분하고, 신규 워크로드가 들어오면 필요한 만큼 자원을 반환 및 재분배합니다. 과잉 프로비저닝 없이 필요한 만큼만 쓰는 환경이 만들어집니다.
모니터링 측면에서는 데이터센터부터 컨테이너 레벨까지 40개 이상의 자체 개발 지표로 GPU 인프라 전체를 추적합니다. 여기에 Daily/Weekly/Monthly 클러스터 현황 리포트가 자동으로 생성되고, 팀별·프로젝트별 사용량 기반 Billing 및 Chargeback을 지원합니다.
실제 사례로, 배터리 선도기업 S사는 분산 운영 중이던 GPU 클러스터를 AIPub으로 통합 관리한 뒤 GPU 활용률을 기존 10% 수준에서 80% 이상으로 끌어올렸습니다. 이것이 GPU FinOps의 출발점입니다.
GPU FinOps 체크리스트
지금 우리 조직의 GPU 비용 관리 수준을 점검해보세요.
✅ GPU 비용을 "할당" 단위가 아닌 "실제 사용량" 단위로 추적하고 있는가?
✅ 팀별, 프로젝트별 GPU 비용을 객관적으로 분리할 수 있는가?
✅ GPU idle time을 정량적으로 측정하고 줄이는 메커니즘이 있는가?
✅ Chargeback 또는 Showback 리포트를 자동으로 생성할 수 있는가?
✅ cost-per-token 수준의 단위 비용 지표를 추적하고 있는가?
하나라도 "아니요"라고 답했다면, GPU 투자 ROI를 높이기 위한 인프라 운영 체계를 재검토할 시점입니다.
GPU FinOps는 "있으면 좋은 기능"이 아닙니다.
GPU 클러스터에 수억 원을 투자한 조직이라면, 그 투자가 어디에 쓰이고 있는지 정확히 알아야 합니다. 그것이 GPU 투자의 ROI를 결정하는 핵심 운영 역량입니다.
AIPub은 GPU 1개를 100블록으로 정밀 분할하고, 그 블록 단위로 사용량을 추적해 팀별·프로젝트별 정확한 비용 배분을 가능하게 합니다. idle time을 실시간으로 탐지해 동적으로 재배분하고, Daily/Weekly/Monthly 리포트로 GPU 투자 ROI를 수치로 입증할 수 있는 환경을 만들어줍니다.
어떤 GPU 구성이 비용 효율이 가장 높은지 데이터로 확인하고 싶다면, RA:X의 벤치마킹 기반 컨설팅이 그 출발점이 될 수 있습니다.
비용은 쌓여가는데 어디서 새는지 모르는 상황, 혼자 고민하지 마세요.
TEN의 전문가와 함께 GPU FinOps 체계를 설계해보세요!